33C3: Analyzing Embedded Operating System Random Number Generators
Last week i gave a talk together with Ali Abbasi at 33C3 on embedded (OS) random number generators (media) (slides) and i thought it worthwhile to elaborate here upon a couple of the issues addressed. Also make sure to check out the related 33C3 presentations on predicting and abusing WPA2/802.11 Group Keys by Mathy Vanhoef and PRNG entropy loss analysis by Vladimir Klebanov and Felix Dörre.
OS CSPRNGs
Since (secure) randomness underpins many components of the wider security ecosystem (such as generation of cryptographic keys and nonces or providing randomness for use in exploit mitigations such as ASLR and stack canaries) and designing and implementing cryptographically secure random number generators (CSPRNGs) is not a trivial undertaking, secure randomness is ideally provided as a system service. Indeed many operating systems include a secure randomness provision service such as /dev/(u)random on Unix-like systems and the CryptGenRandom API on Windows. Many popular security products (such as OpenSSL) are built on top of such OS CSPRNGs.
While extensive work and standardization (eg. NIST SP800-90A) exists for CSPRNG designs in general, these tend to leave open some hard problems such as (among others):
-
Seed Entropy Collection: Since (CS)PRNGs effectively stretch seed entropy into a stream of output bits indistinguishable from random their security is reducable to the quality of seed entropy. Ideally one uses seed entropy drawn from a True Random Number Generator (TRNG) but these are often not available (and certainly cannot be assumed to be available on all systems a given OS is to be deployed on). Accumulating and managing (initialization and runtime) seed entropy (and deciding on adequate sources) thus becomes a particular problem for OS CSPRNGs. -
Reseed Control: In order to limit the window of possible PRNG state recovery attacks and reduce the impact of maliciously manipulated entropy seeping into the system, periodic reseeding of the PRNG (from a pool of entropy collected during runtime) is required. -
Entropy Source Quality Measurement: Overestimating the ‘actual entropy’ present in a pool of collected seed entropy might lead to vulnerability to exhaustive search attacks and as such OS CSPRNGs must be able to decide when the entropic quality of a pool is sufficient to allow for reseeding from it.
Bruce Schneier, John Kelsey and Niels Ferguson designed Yarrow (illustrated in the image below) to address these issues and Yarrow was subsequently adopted by various operating systems (such as OS X, iOS, AIX, FreeBSD and QNX) as the underlying design of their OS CSPRNGs. In order to solve some issues with Yarrow (particularly with regards to entropy estimation), Schneier and Ferguson designed Fortuna as the successor to Yarrow.

Embedded Systems & Entropy Issues
Requiring a source of ‘quality’ entropy before being able to generate secure random numbers is kind of a chicken-and-egg problem. So where do we get our seed entropy from? Ideally we get this from some sort of hardware RNG based on physical phenomena (either quantum-random ones such as radioactive decay or shot noise or non-QR ones such as thermal noise, atmospheric noise or sensor values) but in practice these are often not present so OS CSPRNGs in the world of general-purpose computing tend to rely on ‘unpredictable’ (often associated with user interaction) system events such as mouse movements and keystroke-, disk access- and interrupt request timings instead.

But in the embedded world such entropy sources are often not available. Often there’s little or no user interaction, little or very predictable machine-to-machine interaction and no common input peripherals or disks. Quite simply put: embedded systems are ‘boring’.
Moreover when designing an OS CSPRNG one has to take into account OS design models. In the general-purpose world one can make assumptions about a relatively limited number of operating systems (monolithic or hybrid kernels, many Unix-like and POSIX-compliant systems, etc.) but in the embedded world the sheer number and variety of operating systems makes drafting an OS CSPRNG design suitable for adoption in all of them a challenge. In addition one needs to take into account the varying capabilities and resource constrainedness of embedded systems which can range from high-end carrier-grade networking equipment (think Cisco CRS) to bare minimum, battery operated sensor nodes with only a few hundred bytes of RAM and a few kb of flash memory and 16 or 20 MHz processors (think ATtiny-based devices). This variation of capabilities, with extreme constraints on the lower end of the spectrum, translates to serious design constraints in terms of cryptographic primitive choices, power consumption (constant entropy polling activity becomes unacceptable) and memory (affecting allowable entropy pool and PRNG state sizes).
And even when implementing a particular (rather than designing a generic) OS CSPRNG design, OS developers are faced with another polyculture in terms of hardware and systems. It’s hard to make generalizations about peripherals that might be present. Some systems might have some form of user input (eg. a keypad or touchscreen), some might have an accelerometer, a radio chip, a microphone or sensor input (eg. light, temperature, humidity) but when you have to implement entropy gathering routines for your OS CSPRNG you cannot make such assumptions about the target system (unless you aim at a very, very specific market) and besides, how one interacts with these entropy sources varies from system to system. This often results in a situation where entropy gathering is either left to developers somewhere down the road (eg. vendors putting together a specific embedded system using the OS in question) in the form of ‘implement me’ routines or callback functionality or OS developers rely on any source (however dodgy) known to be always be available, which usually means drawing from system activity (such as system time, IRQs, PIDs, etc.).

Finally, some microprocessor architectures or microcontroller and SoC designs might provide TRNG functionality and when this is present it’s preferable to draw upon this (as many OS CSPRNGs support doing) but one cannot rely on such TRNG functionality as the only seed entropy source alone. For one, such functionality isn’t present in most chips and thus such reliance would adversely affect OS deployability. Secondly TRNGs are usually very slow, generating a limited number of random bits per second which results in slow entropy collection and in turn results in slow OS CSPRNG (re)seeding.
This last issue also means that most embedded OSes that do implement a CSPRNG only implement a non-blocking interface (eg. the /dev/urandom interface on Unix-like systems) in order to prevent insufficient entropy from holding up cryptographic operations and thus adversely affecting system reaction speed. This is particularly problematic in light of the so-called 'boot-time entropy hole' in embedded systems. The boot-time entropy hole is a window of vulnerability during which OS CSPRNG output might be entirely predictable due to it being generated under low entropy conditions (ie. drawn from a non-blocking interface when the CSPRNG is not seeded with sufficient entropy). This window is most likely to occur during boot since here entropy conditions tend to be worst due to little system activity, unavailability of entropy sources and the predictability of boot sequences.
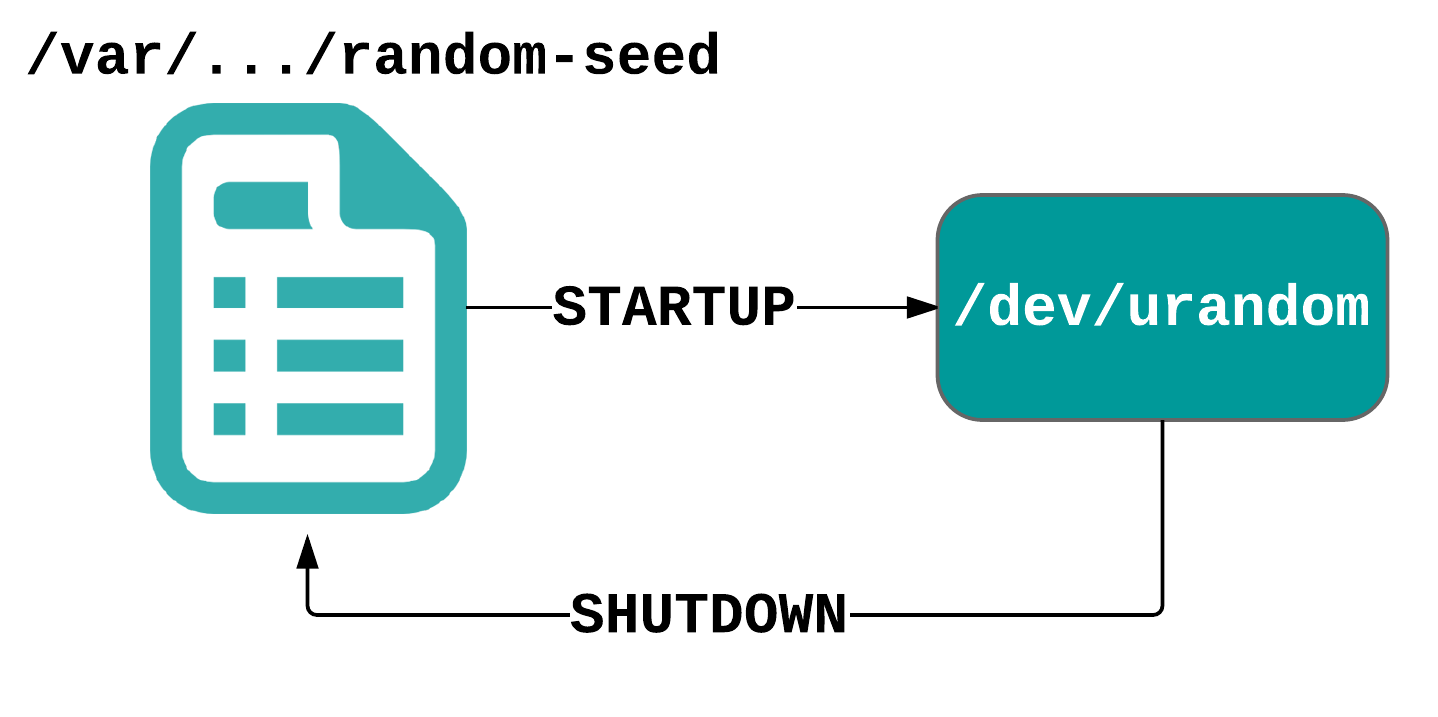
Some operating systems (such as certain general-purpose oriented Linux distros) attempt to tackle this problem by maintaining a so-called ‘seed file’ from which the CSPRNG is (partially) seeded during boot and which gets filled with new random data from CSPRNG output during system shutdown. The problem with porting this approach to the embedded world, however, is that it’s unsuitable for systems without (sufficient) persistent storage and it doesn’t address this issue of the boot-time entropy hole during the first system boot (which is when many embedded systems generate their long-term cryptographic keys).
In the embedded world you can encounter various attempts (of varying dodgy-ness) to address these entropy issues, ranging from including an initial seedfile with the firmware (which should be unique and unpredictable per firmware image as well as keeping in mind an attacker might have access to device firmware) and drawing upon (often public or low-entropy) personalization data (such as serial numbers, usernames, MAC addresses, etc.) to simply including hardcoded, pregenerated keys with the device (which is usually not the best idea as the LittleBlackBox project shows).
This is often a highway to the danger zone as various security issues involving a lack of embedded entropy or (mis)usage of such workarounds show, ranging from Hardcoded X.509 certs & SSH host keys on embedded devices, Weak SSH host keys on Raspberry Pi devices, weak RSA/DSA keys in network devices and weak RSA keys in Taiwan’s Citizen Digital Certificate Smartcards to nonce reuse in ECDSA signatures in Android Bitcoin wallets, attacks on the Android PRNG, weak WPA2 password generation in wireless routers and weak WPA2/802.11 Group Keys in wireless routers.
Works For Me: What’s “random enough”?
As Mathy Vanhoef observed in his 33C3 presentation, the 802.11 standard has an example RNG in Annex M.5 specified rather ambiguously:

The problem of deciding what’s “random enough” (especially for security purposes) isn’t a trivial one though. In order to evaluate this nebulous quality we can look at ‘randomness’ in two places: source entropy and PRNG output. If either isn’t “random enough” PRNG output might be predictable.
PRNG Output Quality
Secure PRNG output should be pseudo-random, that is, it should be indistinguishable from uniform. Various statistical tests can be applied to a sequence to attempt to compare and evaluate a PRNG output sequence to a truly random sequence. Since randomness is a probabilistic property the likely outcome of statistical tests, when applied to a truly random sequence, is known a priori and can be described in probabilistic terms. No finite set of statistical tests is deemed complete but they help in assessing the presence or absence of various statistical ‘patterns’ which, if detected, indicate that the sequence is non-random. As such a PRNG whose output passes a statistical test suite cannot be guaranteed to be pseudo-random but it does rule out the applicability of any of the statistical ‘patterns’ in the test-suite to the PRNG. In order to evaluate the PRNG output quality we commonly turn to two test suites: DieHarder and the NIST Statistical Test Suite (STS).
DieHarder
The DieHarder test suite by Robert G. Brown is designed to ‘push a weak [random number] generator to unambiguous failure (at the e.g. 0.0001% level)’ and serves as a good litmus test to rule out trivially insecure PRNGs. While failing the DieHarder test indicates weak PRNG output quality, passing the DieHarder test is not, however, a guarantee of strong output quality.
NIST Statistical Test Suite (STS)
The NIST Statistical Test Suite (STS) (as specified in NIST SP800-22) was ‘specifically designed for individuals interested in conducting statistical testing of cryptographic (P)RNGs’ and allows for fine-tuned evaluation of PRNG output quality. The NIST STS makes the following assumptions with respect to random binary sequences to be tested:
-
Uniformity: At any point in the generation of a sequence of random or pseudorandom bits, the occurrence of a zero or one is equally likely, i.e., the probability of each is exactly 0.5. -
Scalability: Any test applicable to a sequence can also be applied to subsequences extracted at random. If a sequence is random, then any such extracted subsequence should also be random. Hence, any extracted subsequence should pass any test for randomness. -
Consistency: The behavior of a generator must be consistent across starting values (seeds). It is inadequate to test a PRNG based on the output from a single seed, or an RNG on the basis of an output produced from a single physical output.
Source Entropy Quality
Since the source entropy (sometimes referred to as the noise source) is the root of PRNG security as a whole (since it contains the non-deterministic activity ultimately responsible for the uncertainty associated with PRNG output) it should be properly scrutinized. But as stated in the NIST SP800-90B document:
The validation of an entropy source presents many challenges. No other part of an RBG is so dependent on the technological and environmental details of an implementation. At the same time, the proper operation of the entropy source is essential to the security of an RBG. The developer should make every effort to design an entropy source that can be shown to serve as a consistent source of entropy, producing bitstrings that can provide entropy at a rate that meets (or exceeds) a specified value. In order to design an entropy source that provides an adequate amount of entropy per output bitstring, the developer must be able to accurately estimate the amount of entropy that can be provided by sampling its (digitized) noise source. The developer must also understand the behavior of the other components included in the entropy source, since the interactions between the various components may affect any assessment of the entropy that can be provided by an implementation of the design. For example, if it is known that the raw noise-source output is biased, appropriate conditioning components can be included in the design to reduce that bias to a tolerable level before any bits are output from the entropy source.
In order to evaluate the source entropy quality we commonly turn to the NIST Entropy Source Testing (EST) tool.
NIST Entropy Source Testing (EST) tool
The NIST Entropy Source Testing (EST) tool, developed by the Australian Defence Signals Directorate (DSD), implements the NIST SP800-90B statistical test suite and evaluates whether an input file (drawn from the entropy source(s) to be evaluated) appears to contain independent and identically distributed (IID) samples and estimates the min-entropy. It also allows for min-entropy estimation of non-IID input files. In addition, it provides functionality for evaluating so-called restart datasets which allows evaluating whether entropy source sequences correlate after restarts (which would lead to entropic quality overestimation).
Case Studies
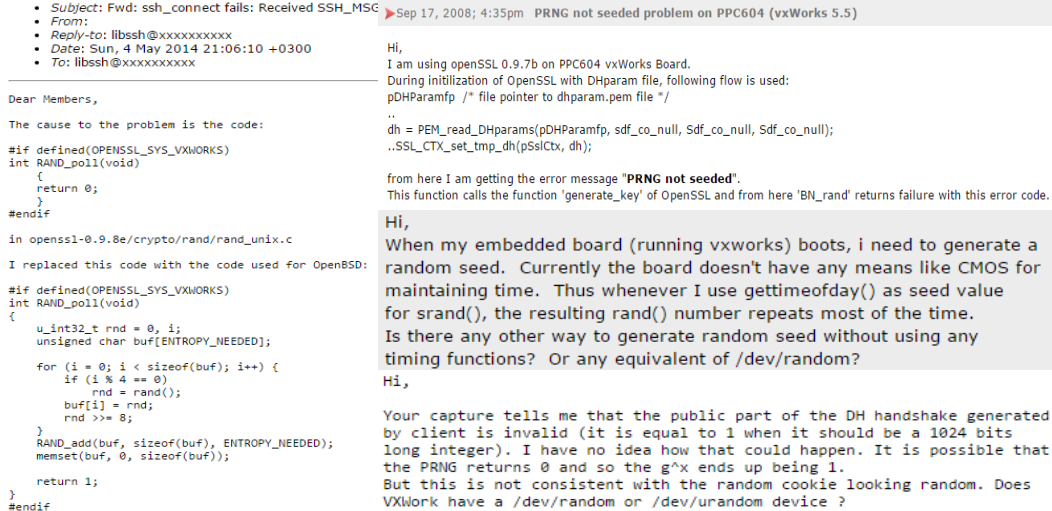
In order to get a better picture of the state of OS CSPRNG presence and quality in embedded operating systems we studied 35 operating systems and found that the majority (60%) of them did not provide any OS CSPRNG functionality (particularly the smaller real-time operating systems (RTOSes) aimed at the most constrained end of the embedded spectrum). VxWorks is one such example of a widely used, commercial (real-time) operating system without an OS CSPRNG. Since many security libraries (eg. OpenSSL, WolfSSL, CryptLib) are built on top of OS CSPRNG assumptions they leave entropy collection up to developers in operating systems which do not provide this functionality. This leads to some worrying attempts at ‘workarounds’ seen on VxWorks developer mailing lists:
And those embedded operating systems that do (at least attempt to) provide an OS CSPRNG tend to make design and implementation mistakes. Since the embedded OSes in our selection that provide an OS CSPRNG are mostly Linux-, BSD- or Windows-based (and often do not have real-time capabilities) we decided to take a closer look at several commercial, closed-source, real-time embedded operating systems that do not derive from these OSes common in the general-purpose world.
Case Study: QNX
QNX is a commercial, Unix-like, POSIX-compliant, real-time operating system with a ‘true’ microkernel architecture aimed primarily at the embedded systems market. Initially released in 1982 for the Intel 8088 and later acquired by BlackBerry it forms the basis of BlackBerry OS, BlackBerry Tablet OS and BlackBerry 10 used in mobile devices as well as forming the basis of Cisco’s IOS-XR used in carrier-grade routers such as the CRS series, the 12000 series and the ASR9000 series. QNX also dominates the automotive market and is found in millions of cars from Audi, Toyota, BMW, Porsche, Honda and Ford (among others) as well as being deployed in highly sensitive embedded systems such as military radios, railway safety, industrial automation, medical devices, UAVs, anti-tank weapons guidance systems and nuclear powerplants.
QNX provides an OS CSPRNG via the Unix-like /dev/random device (with both /dev/urandom and /dev/random being identical non-blocking interfaces). This device provides an interface (via the kernel resource manager) to the random service which runs as a userspace process (since QNX is a microkernel) started after boot by the /etc/rc.d/startup.sh startup script. The service builds its internal pool of random data from sources specified when it is started (in addition to undocumented boot-time entropy collection). These sources may include timers, interrupts, and detailed system runtime information.
The QNX PRNG is based on Yarrow but on the older Yarrow 0.8.71 implementation (having a single entropy pool and not applying a blockcipher to PRNG output) rather than the Yarrow-160 implementation specified in the paper. In addition, QNX Yarrow also diverges from this older implementation in terms of reseed control deviations.
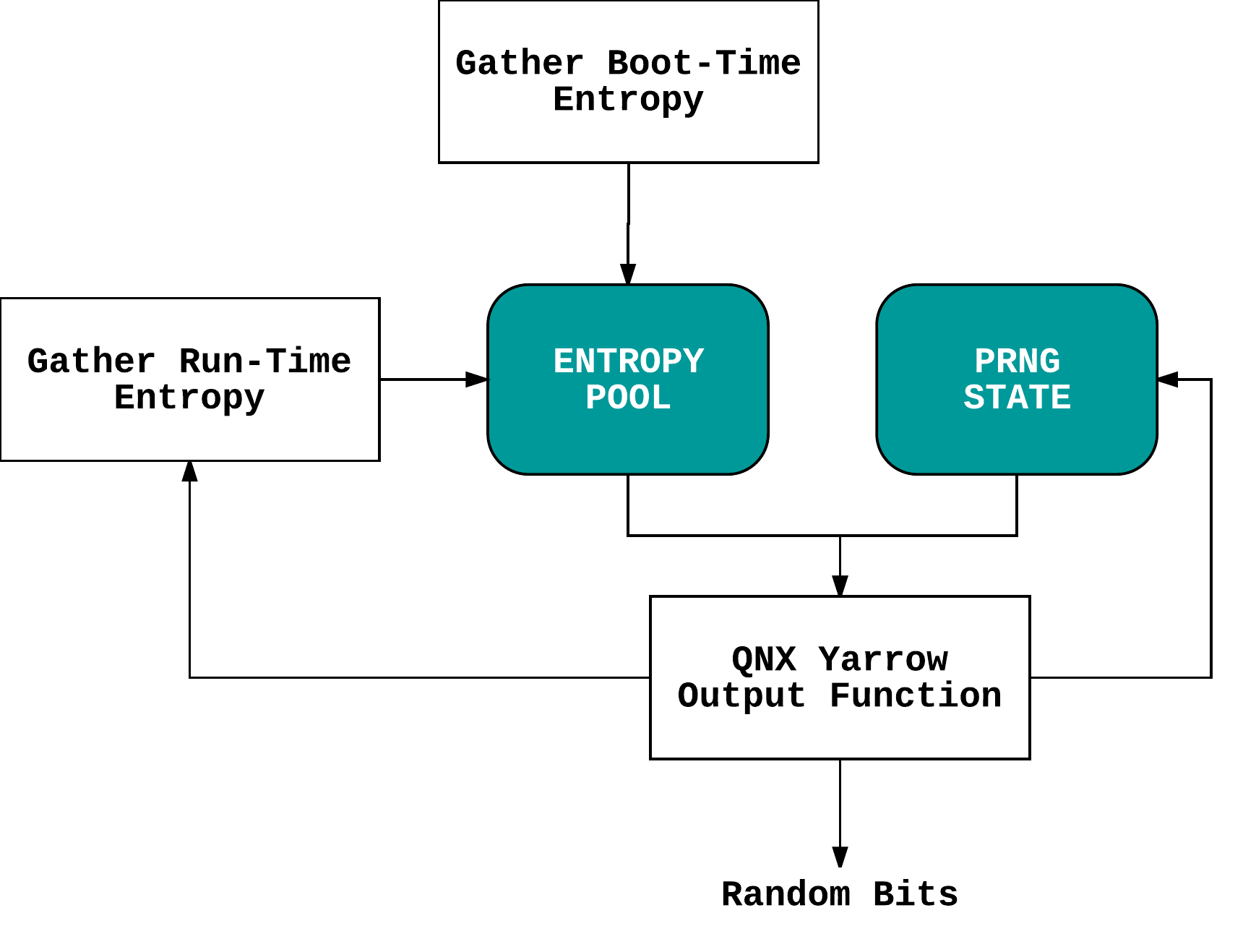
QNX’s /dev/urandom output passes both DieHarder and NIST STS but as it is tailored to embedded systems, its entropy sources are rather lacking. In particular, the undocumented boot-time entropy sources (reconstructed in the image below after reverse engineering) are of less than stellar quality: NIST EST evaluation gives us a min-entropy of 0.0276 which means that QNX boot-time source entropy/noise contains less than 1 bit of actual min-entropy per 8 bits of raw data. Similar shaky results were obtained with regards to restart entropy.

We did not evaluate QNX runtime entropy with NIST EST but static and predictable information elements in process runtime information (uids, flags, priority, etc.) and the way IRQ timings are handled (developers have to manually specify which interrupts to draw from and are advised to choose infrequently triggered interrupts to reduce overhead) are troublesome. This isn’t very relevant for all but the latest of QNX releases (6.6) since in all prior versions reseed control is implemented (ie. functionality is present in system binaries) but never actually invoked which means reseeding never takes place and runtime entropy is idly accumulated in the entropy pool while the only entropy present in the PRNG comes from boottime entropy. Needless to say, this is a dangerous situation. In QNX 6.6 some form of custom reseed control is implemented (in the yarrow_do_sha1 and yarrow_make_new_state functions to be precisely):
yarrow_do_sha1(yarrow_t *p, yarrow_gen_ctx_t *ctx)
{
SHA1Init(&sha);
IncGaloisCounter5X32(p->pool.state);
sha.state[0] ^= p->pool.state[4];
sha.state[1] ^= p->pool.state[3];
sha.state[2] ^= p->pool.state[2];
sha.state[3] ^= p->pool.state[1];
sha.state[4] ^= p->pool.state[0];
SHA1Update(&sha, ctx->iv, 20);
SHA1Update(&sha, ctx->out, 20);
SHA1Final(ctx->out, &sha);
}
Where reseeding from the pool takes place during PRNG initialization and outputting but no entropy estimation is done on the pool whatsoever (which is was one of the Yarrow design goals) which means there are no guarantees about runtime entropy quality during reseeding.
I disclosed these issues to BlackBerry upon discovery and they rapidly responded by drafting suggestions into a new Fortuna-based PRNG which should be available in patches for QNX 6.6 and will be the default for the upcoming QNX 7.
Case Study: ██████████
Another embedded operating system we studied we can’t name because of an NDA but it’s a POSIX-compliant RTOS used in highly sensitive environments such as civilian (eg. Airbus A380) and military (eg. Lockheed Martin F-35 Lightning II (JSF)) avionics, components within the Joint Tactical Radio System and components of the International Space Station (ISS).
The OS provides a PRNG via a /dev/urandom interface with two main underlying functions urandom_read (filling a buffer with random bytes) and urandom_write ((re)seeding the PRNG using only the 1st 4 bytes from a supplied buffer). After reverse engineering the PRNG i found out it was based on the glibc BSD random(3) PRNG with custom constants, which is not a secure random number generator. To make matters worse, the PRNG was vulnerable to a local reseed attack since the /dev/urandom interface was world-writable by default allowing any attacker with limited privileges to control the PRNG internal state (and hence output) on a system-wide level (allowing for eg. influencing cryptographic keys generated for users with higher privileges). But the worst mistake was probably the fact that the PRNG’s initialization function simply consumes a static 32-bit seed which is identical for every OS deployment. In the further absence of reseed control this means PRNG output is completely predictable to a remote attacker with the only source of uncertainty being the number of bytes consumed from the PRNG (thus advancing the state offset) before drawing for it to generate a particular cryptographic secret. Since this uncertainty is very reasonably bounded (it’s quite unlikely more than 4GB have been read from /dev/urandom before generating a particular target secret, thus bounding the search space by 2**32) an attacker targeting eg. a public key generated on this OS can simply clone the PRNG from the known seed and mount an exhaustive search for the correct state offset until a matching public/private keypair has been found allowing for trivial private key recovery attacks (among other attacks exploiting this PRNG’s weakness) as shown in the image below. This attack is quite a bit more powerful than even an attack targeting the fact that PRNG algorithm itself is insecure.

Takeaways and Open Problems
Of course the issue here isn’t with these OSes in specific (seeing as how they were virtually the only non-Linux/BSD/Windows based OSes in our selection of 35 operating systems to even provide an OS CSPRNG in the first place) but with the general state of embedded systems security. It’s common wisdom in infosec circles that ‘embedded device security sucks’ and problems with embedded random number generators and low entropy aren’t anything new but time and again research shows embedded systems all across the spectrum (from consumer gadgets with barely any capabilities to highly sensitive and critical systems running mature, commercial operating systems) significantly lag behind what we’ve come to expect of general-purpose devices.
There’s many reasons for this and i will try to address some of them (with regards to embedded binary security) in my talk ‘Ghost in the Machine: Challenges in Embedded Binary Security’ at Enigma 2017 in Oakland at the end of this month. With regards to embedded randomness, however, some of the major issues are:
-
Low Entropy Environment: There’s an absence of omnipresent, high-quality entropy sources to rely on -
Polyculture: The polyculture of software and hardware in the embedded world makes it hard to draft generalized designs suitable for a wide range of target systems and often ends up with a situation where there is a lot of burden on end developers to implement eg. device-specific entropy gathering routines (which often means this is done badly or not at all). -
Memory and Code Constraints: Limited available program and data memory means PRNGs will have to use lightweight cryptographic primitives and small internal states and entropy pools -
Speed Constraints: Boot and reaction time requirements as well as general low overhead considerations mean interfaces to OS CSPRNGs will be always non-blocking and sufficient entropy must be available rapidly upon device boot. -
Power Consumption Constraints: Limited power consumption requirements (especially for battery-operated devices) means CSPRNG designs will have to be simple and should not poll for entropy gathering or reseed control too frequently. -
Lack of Scrutiny: Compared to the general purpose world a lot of the embedded world is still unexplored terrain, resulting in insecure code remaining active for prolonged periods of time (which is compounded by the omnipresent patching issues in embedded systems). The common wisdom ‘just use /dev/urandom for secure randomness’ shouldn’t land developers in trouble and as such more attention for the security of widely used embedded operating systems is warranted.
Finally, there’s a lack of standardized (de-facto or otherwise) reference designs for secure embedded random number generators taking the problems that OS CSPRNG designs such as Yarrow or Fortuna were designed to tackle into account. A concentrated effort to address (some of) the above issues (in the vein of the μNaCl Networking and Cryptography library for microcontrollers by Bernstein, Lange and Schwabe) seems to be overdue.
samvartaka 03 January 2017