The flawed crypto of Hacking Team's 'core-packer' malware crypter
Warning: The repository associated with this post contains malicious binaries (core, core_packed, soldier, soldier_packed) for educational purposes. Don’t go around toying with them if you don’t know what you’re doing.
A couple of days ago i came across this post detailing a joint project between Ethan Heilman and Will Cummings discussing Hacking Team’s crypter named ‘core-packer’. The crypter’s source was leaked online after the Hacking Team compromise of July 2015. As Heilman notes despite the name ‘core-packer’ is a crypter as it doesn’t perform compression but rather uses anti-analysis functionality (including encryption) to obfuscate malicious PEs in order to evade anti-virus products. Taking a look at ‘core-packer’ provides an interesting glimpse at the quality (or lack thereof) of ‘government-grade’ commercial malware products.
Heilman’s discussion of the crypter is fairly complete and mentions the important distinction between the common use of cryptography and the use of cryptography in anti-anti-virus techniques: while the former seeks to guarantee security properties like confidentiality, integrity, etc. (preferably on a long-term basis) the latter simply seeks to force detection solutions to integrate code that recognizes the packer, locates the cryptographic keying material and applies the decryption process in the appropriate fashion in order to obtain the original malicious binary in the hopes that the performance penalty imposed by integrating this kind of code for every crypter out there is simply too much. So while the usage of ciphers like TEA or RC4 would be ill-advised (to say the least) in regular cryptographic contexts in the case of ‘core-packer’ that’s not much of an issue. Given that the keying material is stored together with the ciphertext the hardly is the guarantee of long-term confidentiality.
But that doesn’t mean the developers of ‘core-packer’ didn’t mess up anyway. The crypter works by iterating over all sections in a PE and when a section is not shared (IMAGE_SCN_MEM_SHARED) and it is either executable (IMAGE_SCN_MEM_EXECUTE) or named .data the section is encrypted. As can be seen here if the PE in question is a DLL the section is encrypted using RC4 while if it is an executable it is encrypted using TEA. Key generation is done as follows:
srand(GetTickCount()); // initialize for (rand)
(...)
char passKey[16];
for(int i =0; i < sizeof(passKey); i++)
passKey[i] = rand() % 256;
Where the 128-bit key is used directly for TEA and used to initialize the S-Box of RC4 using its Key Scheduling Algorithm (KSA).
Both ciphers, however, are used in fatally flawed ways.
That damn penguin again
Take a look at the crypter source part handling the encryption of section data using TEA:
{
uint32_t *key = (uint32_t *) rc4sbox;
LPDWORD encptr = (LPDWORD) pProcessSection->RawData();
encptr += 0x800;
for(DWORD dwPtr = 0x2000; dwPtr < pProcessSection->SizeOfRawData(); dwPtr += 8, encptr += 2)
{ // no encryption!
//if (encptr[0] == 0xCCCCCCCC || encptr[1] == 0xCCCCCCCC)
//{ // alignment .. skip
//}
//else
//{ // encrypt block!
tea_encrypt((uint32_t *) encptr, key);
//}
/*DWORD tmp = encptr[0]
= encptr[1];*/
}
pProcessSection->hide(true);
//pSectionHeader->Characteristics ^= IMAGE_SCN_MEM_EXECUTE;
//pSectionHeader->Characteristics &= IMAGE_SCN_MEM_READ;
}
As we can see the code iterates over the data in a block-wise fashion and applies TEA to each block seperately, ie. it uses the cipher in the Electronic Codebook (ECB) mode of operation. It is more or less common knowledge (or at least, should be) that ECB mode replicates plaintext patterns in its ciphertext since identical plaintext blocks get mapped to identical ciphertext blocks as shown by the notorious ‘ECB penguin’:

What this means for the crypter is that identical plaintext block patterns within or among sections are preserved in the ciphertext.
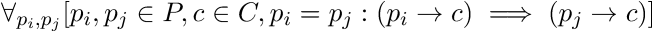
Hence anyone seeking to detect crypted versions of known malicious executable can do so by seeing whether this ‘ECB constraint’ holds over a supicious executable to confirm whether it is a crypted version of this or that malicious executable or not. This is made even worse by using TEA as their choice of blockcipher since its small block size (64 bits = 8 bytes) means more blocks per given plaintext and hence a higher chance of identical blocks (and thus a more reliable constraint).
I wrote a little proof-of-concept tool to detect whether, given a set of profiles for known malicious executables, a suspicious PE corresponds to a ‘core-packer’ crypted version. Given that checking whether this constraint holds given a particular profile is faster than the process of crypter detection and automatic key extraction from the stub it defeats the crypter’s purpose.
The proof-of-concept i wrote extracts rather crude and strict ‘profiles’ (it simply finds identical blocks within a section and the offsets they correspond to) but these constraints could be relaxed to accomodate more flexible ways of abusing this flaw (though a sufficiently fine-grained profile would be necessary to avoid false positives, especially with a large profile database). Either way, the bottomline is that ‘core-packer’ uses TEA in ECB mode and even if its purpose is not to offer ‘strong cryptographic’ guarantees on confidentiality it fails in its obfuscation purpose this way.
Parallel streams, known plaintexts and statistics
But what about the crypter’s use of RC4 for DLLs? Take a look at the relevant part of the crypter source:
for(int i = 0; i < pInfectMe->NumberOfSections(); i++)
{ // each section must be packed
if (pInfectMe->IsDLL())
{
init_sbox(rc4sbox);
init_sbox_key(rc4sbox, (BYTE *) passKey, 16);
}
(...)
else if ((pSectionHeader->Characteristics & IMAGE_SCN_MEM_EXECUTE) == IMAGE_SCN_MEM_EXECUTE)
{
//pSectionHeader->Characteristics |= 0x02;
if (pInfectMe->IsDLL())
cypher_msg(rc4sbox, (PBYTE) pProcessSection->RawData(), pProcessSection->SizeOfRawData());
Since RC4 is a streamcipher there is no need for either padding or dividing the section data into blocks. One simply takes the plaintext and XORs it on a byte-by-byte basis with the keystream generated by the RC4 Pseudorandom Generation Algorithm (PRGA). The mistake made by the developers of ‘core-packer’, however, lies in the fact that they re-initialize the KSA for every section and do so without using a nonce (since the RC4 specifications do not require one to be used). This means that if a single key is used to encrypt multiple plaintexts the same keystream will be used (since the keystream is deterministically generated based on the initial ‘seed’ key) for all of them. This results in what is known as a collection of ‘parallel ciphertexts’, ie. a collection of ciphertexts sharing the same keystream. This results in two types of attacks we can mount against the crypter for detection purposes.
Known Plaintext Attack on Parallel Ciphertexts
The first of these is a known plaintext attack (KPA).

As can be seen in the above image it is trivial to obtain a keystream segment of length n from offset i to offset i+n if i have a known (or probable) plaintext segment of length n at the same offset. A simple XOR between the ciphertext and known plaintext will result in the keystream segment corresponding to that offset. A well-designed streamcipher ensures that such KPAs yielding keystream derivation do not allow for recovery of the internal state of the PRGA (and hence recovery of other keystream fragments or even the seed key). But if we have a set of parallel ciphertexts we can use such a KPA to derive keystream at offset i in one ciphertext and apply it at the same offset to another ciphertext (since they were encrypted using the same keystream) and hence obtain another plaintext fragment.
Since we are not looking to obtain unknown plaintext (as would be the case in a regular KPA against parallel ciphertexts) but rather seek to confirm the presence of several known plaintext fragments (which an anti-virus product would have in the form of signatures), in order to confirm a particular suspicious binary is in fact a ‘core-packer’ crypted version of a known malicious binary, exploiting this weakness is easier than the usual cryptanalysis approach for this scenario.
Given a set of probable plaintext fragments (coupled to a particular offset within a particular PE section) extracted from a malicious binary we can confirm (with a False Positive/False Negative ratio dependant upon the amount of plaintext fragments we have) our suspect binary is indeed a crypted version of this or that malicious binary by deriving the keystreams for all probable plaintexts in one section and applying them to the corresponding offsets in subsequent sections and confirming whether our probable plaintexts for those offsets within those sections match.
My proof-of-concept tool does this in the following fashion:
# Derive keystream from known plaintext and ciphertext
known_plaintext = offset_list[0]['plaintext']
keystream = self.xor_strings(known_plaintext, section_data[offset: offset+len(known_plaintext)])
# Check whether keystream holds over other known plaintexts at identical offsets
for i in xrange(1, len(offset_list)):
section = self.get_section_by_name(pe, offset_list[i]['section_name'])
assert(section != None)
# Has to be a core-packer section encryption candidate
assert((hasattr(section, 'IMAGE_SCN_MEM_EXECUTE') or (section.Name[:5] == ".data")))
section_data = section.get_data()
assert(len(section_data) > offset)
known_plaintext = offset_list[i]['plaintext']
candidate_plaintext = self.xor_strings(section_data[offset: offset+len(known_plaintext)], keystream)
if(candidate_plaintext != known_plaintext):
return False
Parallel Ciphertexts and N-Gram model preservation
A second approach abusing this flawed usage of streamciphers relies on the fact that a XOR operation between the elements an (even-numbered) set of parallel ciphertexts results in a XOR operation between the corresponding plaintexts:
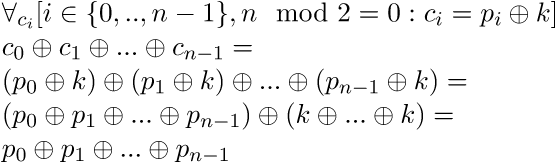
Extracting this XOR ‘product’ from an unpacked and packed version of a given binary (see below for the binaries in question) as follows:
def get_blob(self, pe, use_sections):
data_blob = ""
# Use even number of sections (at least 2) to 'cancel out' keystreams
assert((len(use_sections) >= 2) and (len(use_sections) % 2 == 0))
for section in pe.sections:
secname = section.Name[:section.Name.index("\x00")]
# Is target core-packer section and under our consideration?
if((hasattr(section, 'IMAGE_SCN_MEM_EXECUTE') or (secname == ".data")) and (secname in use_sections)):
section_data = section.get_data()
# Set data_blob to XOR between current content and section ciphertext
if(data_blob == ""):
data_blob = section_data
else:
data_blob = self.xor_strings(data_blob[:min(len(section_data), len(data_blob))], section_data[:min(len(section_data), len(data_blob))])
return data_blob
Will yield the same binary ‘blob’ of XORed plaintexts:
$ sha1sum core_blob
145ab4b99a493ab16e3a5ff81a91b3b91c97cd9a core_blob
$ sha1sum core_packed_blob
145ab4b99a493ab16e3a5ff81a91b3b91c97cd9a core_packed_blob
An interesting property of the above scenario is that the resulting XOR-product of the plaintexts has a very particular statistical profile (as seen in the binvis.io generated image of core_blob below) which we can use to confirm a suspect binary is a ‘core-packer’ crypted version of a known malicious binary.

We can do this by, given a known malicious binary, building a so-called n-gram model of the XOR-product of the PE sections which would be encrypted using ‘core-packer’ (ie. its executable sections and the .data section). Given this XOR-product ‘blob’ the n-gram model lists, for a given length n, the relative frequencies of the various n-grams (that is, sequences of n bytes) occurring in the ‘blob’.
Now, given a suspect binary we obtain the same XOR-product of the applicable sections, determine its n-gram model and compare it against our database of n-gram models for known malicious binaries. If the total ‘error’ (defined as the sum of absolute differences in relative frequencies for a given n-gram in two between n-gram models) is below an (experientially determined) threshold value t we have a match and can confirm that our suspect binary is in fact a crypted version of a known malicious binary. Here the false positive and false negative rates depend on n-gram size n and treshold value t.
The proof-of-concept tool implements this as follows:
class NgramProfiler:
def get_ngrams(self, data, n):
return list(NGram(N = n).ngrams(data))
def get_ngram_absolute_frequencies(self, data, n):
return NGram([data], N= n, pad_len=0)._grams
def get_ngram_relative_frequencies(self, data, n):
l = len(data)
absolute = self.get_ngram_absolute_frequencies(data, n)
relative = defaultdict(float)
for gram in absolute:
relative[gram] = (absolute[gram][data] / float(l))
return relative
def error(self, f, lookup_table):
e = 0.0
for gram in lookup_table:
e += abs(lookup_table[gram] - f[gram])
return e
(...)
# Obtains statistical profile for target PE
def get_statistical_profile(self, pe, use_sections, n):
data_blob = ""
# Use even number of sections (at least 2) to 'cancel out' keystreams
assert((len(use_sections) >= 2) and (len(use_sections) % 2 == 0))
for section in pe.sections:
secname = section.Name[:section.Name.index("\x00")]
# Is target core-packer section and under our consideration?
if((hasattr(section, 'IMAGE_SCN_MEM_EXECUTE') or (secname == ".data")) and (secname in use_sections)):
section_data = section.get_data()
# Set data_blob to XOR between current content and section ciphertext
if(data_blob == ""):
data_blob = section_data
else:
data_blob = self.xor_strings(data_blob[:min(len(section_data), len(data_blob))], section_data[:min(len(section_data), len(data_blob))])
# Get n-gram profile
return NgramProfiler().get_ngram_relative_frequencies(data_blob, n)
def dll_check_statistical_profiles(self, pe, profiles):
print "[*]Matching statistical profiles..."
for profile in stat_profiles:
# Determine n-gram profile of parallel plaintexts in packed file
p1 = self.get_statistical_profile(pe, stat_profiles[profile]['sections'], stat_profiles[profile]['n'])
# Compare with n-gram profile of known malicious file
p2 = [stat_profiles[profile]['profile']]
# Check whether error is below error margin
e = min([NgramProfiler().error(p1, x) for x in p2])
if(e <= stat_profiles[profile]['error_margin']):
print "[!]File matches malicious profile of '%s'!" % profile
return True
print "[+]File matches no known malicious profiles"
return False
Another, more general, approach (ab)using the above weaknesses allows one to distinguish between the XOR-product of parallel ciphertexts and the XOR-product of arbitrary data. As Eric Filiol describes this effectively comes down to distinguishing random from non-random data and can be done by taking the XOR-product of what you suspect to be parallel ciphertexts, counting the number of null bytes z and testing whether z has normal distribution law:
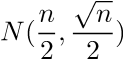
If so we are not dealing with parallel ciphertexts. In the case that we are z has normal distribution law (where p > 1/2 is the probability for a bit to be zero):
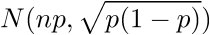
Using this distinguishing attack we can determine whether the sections of a suspect binary are parallel ciphertexts and hence encrypted by a (badly implemented) streamcipher. This holds for all crypters operating in this fashion (not just ‘core-packer’) and hence can be a useful heuristic.
Building, Testing & Detecting ‘core-packer’
In order to test ‘core-packer’ and the techniques discussed above i set up a virtual machine running Windows XP and built the 32-bit version of the crypter using Microsoft Visual Studio 2012. The following modifications to the solution are necessary for it to work:
- Link with /SAFESEH:NO
Project -> core-packer properties -> Linker -> Advanced -> Image Has Safe Exception Handlers -> No - Compile for WinXP
Project -> core-packer properties -> General -> Platform Toolset -> Visual Studio 2012 - Windows XP (v110_xp)
We also need to make sure the Microsoft Visual C++ 2012 redistributable package (x86) is installed on our VM.
As noted by Heilman running the crypter on random PEs caused the crypter either to crash or produce corrupted executables so i simply ran it on pre-compiled Hacking Team malware samples (RCS-Agent for a sample DLL and RCS-Soldier for a sample executable, sources can be found here and here) which were then crypted without problems:
> packer32.exe core core_packed
[CONFIG] random file sectoin: C:\WINDOWS\system32\dmutil.dll
Input file is DLL!
.pedll32/32bit section found in code
Size of raw data: 1400
Virtual size: 126b
RVA: 21000
Virtual Address: 00421000
[CONFIG] Section Name: .calc
[CONFIG] base: 0
[CONFIG] size: 1400
> packer32.exe soldier soldier_packed
[CONFIG] random file sectoin: C:\WINDOWS\system32\d3d8.dll
Input file is EXECUTABLE
.peexe32/32bit section found in code
Size of raw data: c00
Virtual size: b95
RVA: 23000
Virtual Address: 00423000
**WARNING** LOAD_CONFIG Data Directory isn't NULL! Removing!
[CONFIG] Section Name: .hermit
[CONFIG] base: 0
[CONFIG] size: c00
The following SHA1 digests correspond to the binaries involved:
core: f0f14b8c20c727721188cb14071ad8997cef2181
core_packed: 100350f5cae5b4bb39052244e8498e98da0e33ad
soldier: 5fcca76ea037d311bc5614c16da91a15a5a9c44e
soldier_packed: 0d4addd4784dcae45146145344f9b8e48edd4407
I also uploaded them to virustotal which showed some disappointing detection results (considering the Hacking Team malware and crypter are pretty high profile and have been out there for quite a bit now):
I generated profiles (for ECB identical block detection, known plaintext detection and n-gram profile detection) for the core and soldier binaries:
$python core_packer_detect.py --file soldier_packed --get-ecb .text .data
.Hacking Team 'core-packer' PoC detector.
(c) 2015, Jos Wetzels
{'.data': [[7840, 7912, 8056, 8200, 8560, 8632, 8848], [4088, 4120, 4152, 4184,
4264, 4488, 4712, 9456], [4112, 4256, 9448], [7152, 7264, 7336, 7408, 776
(...)
$python core_packer_detect.py --file core_packed --get-stats .text .data --n 1
.Hacking Team 'core-packer' PoC detector.
(c) 2015, Jos Wetzels
defaultdict(<type 'float'>, {'\x00': 0.09117759146341463, '\x83': 0.022389481707317072, '\x04': 0.030892721036585365, '\x87': 0.000857469512195122,
(...)
And used the proof-of-concept tool against the packed versions as follows:
$python core_packer_detect.py --file core_packed
.Hacking Team 'core-packer' PoC detector.
(c) 2015, Jos Wetzels
[*]Matching known plaintext profiles...
[!]File matches malicious profile of 'rcs_agent'!
$python core_packer_detect.py --file soldier_packed
.Hacking Team 'core-packer' PoC detector.
(c) 2015, Jos Wetzels
[*]Matching known ECB-mode profiles...
[!]File matches malicious profile of 'rcs_soldier'!
The lesson here is that while ‘cryptographically secure’ might not be as much of an issue with obfuscation tools (such as crypters) as with other applications of cryptography, poorly implemented crypto can still completely defeat its own purpose. In this case for better rather than for worse.
samvartaka 13 September 2015